Installation¶
Requirements¶
Mineotaur requires Java 8 or higher, which can be download here: http://www.oracle.com/technetwork/java/javase/downloads/index-jsp-138363.html
If you want to build Mineotaur from source, you will also need Maven: https://maven.apache.org/
Generting a Mineotaur instance from text files¶
To generate a Mineotaur instance, you have to provide three input files: a data file containing all the measurements you want to include in Mineotaur, a label file containing the annotations assigned to the objects in Mineotaur and a file setting several options in Mineotaur. A sample for all input file can be downloaded here..
Data file¶
The input data file can ?SV (? Separated Values), where ? is an appropriate separator set in the options file (e.g. TSV - Tab Separated Values). Each line describes a set of measurements for a descriptive object, which is a unique obejct of interest in the experiment. Each descriptive object should be connected to a group object. Examples: descriptive object - cell, group object - gene. The file is consists of a header, an object and a type descriptor and the data lines.
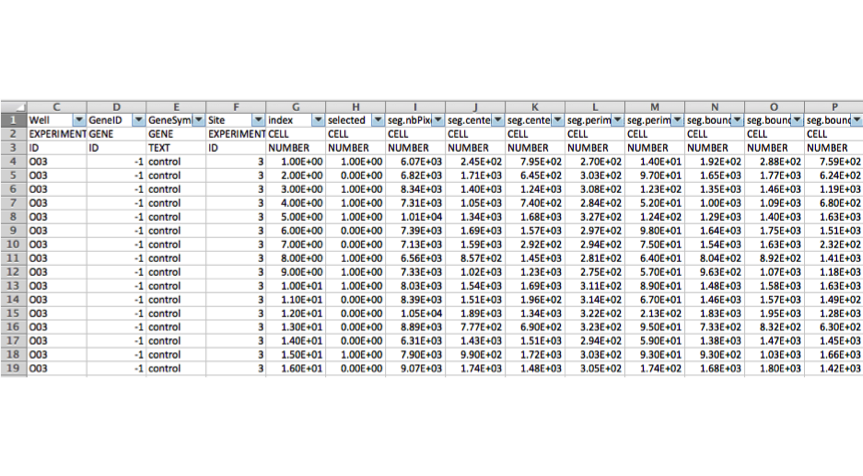
Header¶
The first line of the data file. The header describes the names of the properties to be stored in the Mineotaur. Each name must be unique for a given object type and should not contain non-alphanumerical characters.
Object descriptor¶
The second line of the data file. The object descriptor describes what kind of real-world object does the respective column belongs to. The object descriptors can be any string. However it is advised to give semantically relevant names to future usage. Examples: Gene, Cell, Experiment.
Type descriptor¶
The third line of the data file. The type descriptor describes the data type for each column. The following types are accepted: * ID: identifier for a given object. Can be multiple IDs for one object type. * NUMBER: numerical data. Each numerical column of the descriptive can be queried. * TEXT: non-numerical data.
Data lines¶
Each line after starting from the fourth should contain the actual measurements for a descriptive object and other meatadat connecting them to experimental conditions.
Label file¶
The label file contain the annotations for the group level objects. For example, what genes were picked up as hits in a study. The label file consists of a header line and multiple label lines.
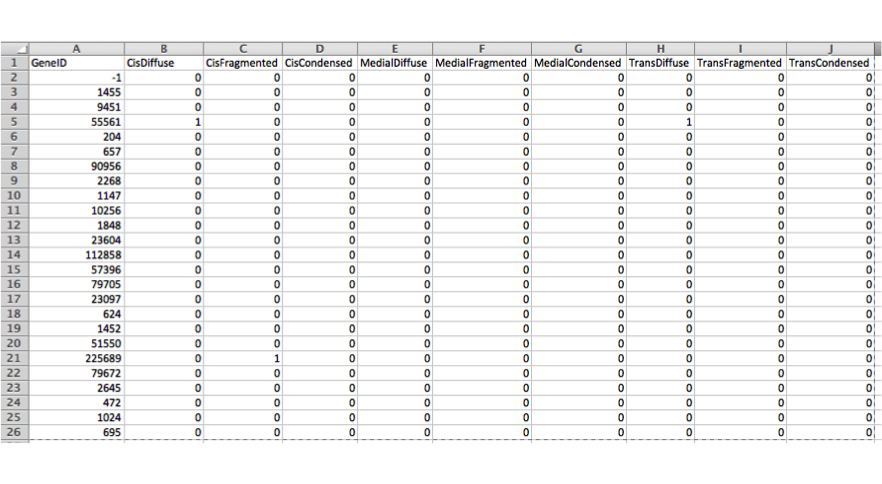
Header¶
The first line of the label file. The first column contains the name of the group object ID property from the data file, while the rest of the columns contain the annotations.
Label lines¶
Each line starting from the second contains a group object ID and a 1 for each annotation assigned to the group object or 0, otherwise.
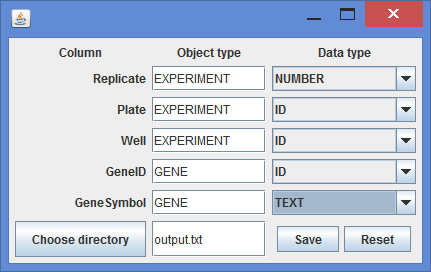
Metadata wizard¶
Mineotaur also provides a graphical interface to provide the metadata required for a standard data file by starting the wizard from the command line:
java -jar <path_to_jar file> -metadata <data_file> <spearator_character>
Options file¶
The options describes metadata for the instance generation. All options are in the following format: option_name = option_value. The following options can be set:
- (REQUIRED) name: name of the instance
- group: name of the group object (same as described in the data file). Default: GENE
- groupName: group object ID (same as described in the data file). Default: geneID
- descriptive: name of the group object (same as described in the data file). Default: CELL
- total_memory: the amount of memory can be used by Neo4J. Default: 4G
- separator: character used to separate columns in the data and the label files. Default: \t
- overwrite: whether to overwrite the current instance with the same name. Default: true
Please note that the different object caching methods of the operating systems might affect the performance of Neo4J so it is advised to set the amount of total memory after some experimenting. Under OSX, it is also advised to perform a memory clean from time to time since a lot of object is kept in the memory, leading to performance loss in the long run.
Generation from command line¶
- Download the latest jar file from http://www.mineotaur.org.
- Create a property file, a data file and a label file (see documentation and example input data)
- Start the data import with the following command:
java -jar <path_to_jar file> -import mineotaur.input chia_sample.tsv chia_labels.tsv
- After the database creation is completed you can start your Mineotaur instance with the following command:
java –jar <path_to_jar file> -start <instance_name>
- You can start querying at http://127.0.0.1:8080 in your browser.
Generation using the wizard¶
- Download the latest jar file from http://www.mineotaur.org.
- Create a property file, a data file and a label file (see documentation and example input data)
- Start the data import with the following command:
java -jar <path_to_jar file> -wizard
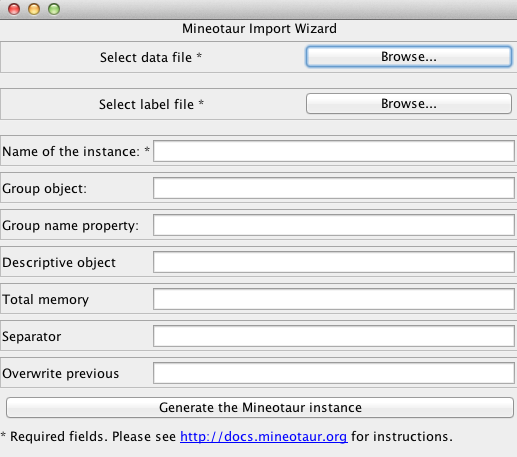
- After the database creation is completed you can start your Mineotaur instance with the following command:
java –jar <path_to_jar file> -start <instance_name>
- You can start querying at http://127.0.0.1:8080 in your browser.